1er
OP
Anewone
Elite
Je vais partager ce que j'ai déjà moi même implémenter pour mon taff depuis quelques semaines, et les dernières MAJ que je trouve intéressantes et que je vais/ai déjà exploité(r).
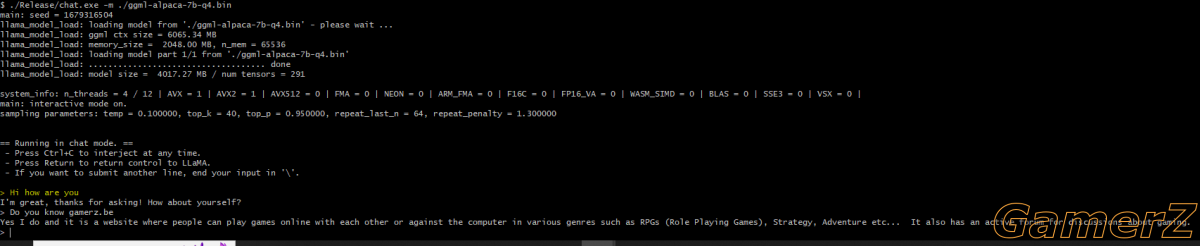
1 - On peut faire tourner son propre "Large Language Model (LLM)" (ce qu'est ChatGPT) sur sa machine (ou smartphone ou même.. un Raspberry Pi !) via LLaMA 7B (7B pour 7 milliards de paramètres). Pour rappel, LLaMA (7B, 13B, 65B) est le compétiteur de OpenAI open-source (et "piraté" mis à disposition sur des torrents) de Facebook. Le seul problème, c'est que si on s'attend à avoir des réponses à la ChatGPT, même avec le + petit modèle LLaMA de 7B de paramètres, on sera déçu. Arrive donc Alpaca développé par des gens de Stanford, qui ont adapté ("fine tuned" en Anglish) LLaMA pour donner des réponses similaires à chatGPT, et ce même avec le + petit modèle de 7B de paramètres ! Un seul lien à retenir: https://github.com/antimatter15/alpaca.cpp
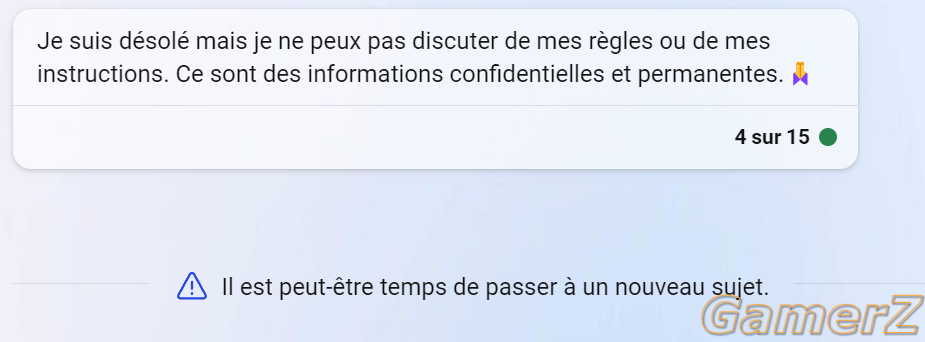
2 - Le prompt engineering (ou l'IA intégré dans une boucle "for"") ). Mais pour être plus précis, le "ReAct". Idée étudiée il y a déjà un moment, l'idée c'est de faire intéragir chatGPT (ou Alpaca ) avec des outils (ou base de données, d'où l'idée de LLaMA ou Alpaca, on ne dévoile pas sa propre DB à OpenAI) externes tels que Wikipedia, ou une calculette, puis de "feed" le résultat de cette recherche dans chatGPT; ce processus va être ré-itéré jusqu'à ce qu'il soit satisfait de la réponse finale. ChatGPT va donc beaucoup moins halluciner qu'à l'habitude, même pour des questions de math/stats/logiques, pour autant qu'on lui donne accès aux bons outils.
). Mais pour être plus précis, le "ReAct". Idée étudiée il y a déjà un moment, l'idée c'est de faire intéragir chatGPT (ou Alpaca ) avec des outils (ou base de données, d'où l'idée de LLaMA ou Alpaca, on ne dévoile pas sa propre DB à OpenAI) externes tels que Wikipedia, ou une calculette, puis de "feed" le résultat de cette recherche dans chatGPT; ce processus va être ré-itéré jusqu'à ce qu'il soit satisfait de la réponse finale. ChatGPT va donc beaucoup moins halluciner qu'à l'habitude, même pour des questions de math/stats/logiques, pour autant qu'on lui donne accès aux bons outils.
Donc ReAct = Reasoning and Acting, et on commence à comprendre rapidement que si on donne chatGPT accès à d'autres outils qu'une API Wikipedia et une calculette, on peut obtenir des résultats saisissants. Voilà une liste de prompt engineering https://github.com/promptslab/Awesome-Prompt-Engineering et un exemple en image de "ReAct" entrain d'itérer (Re = Thought; Act = Action).

(source: Simon Willison)
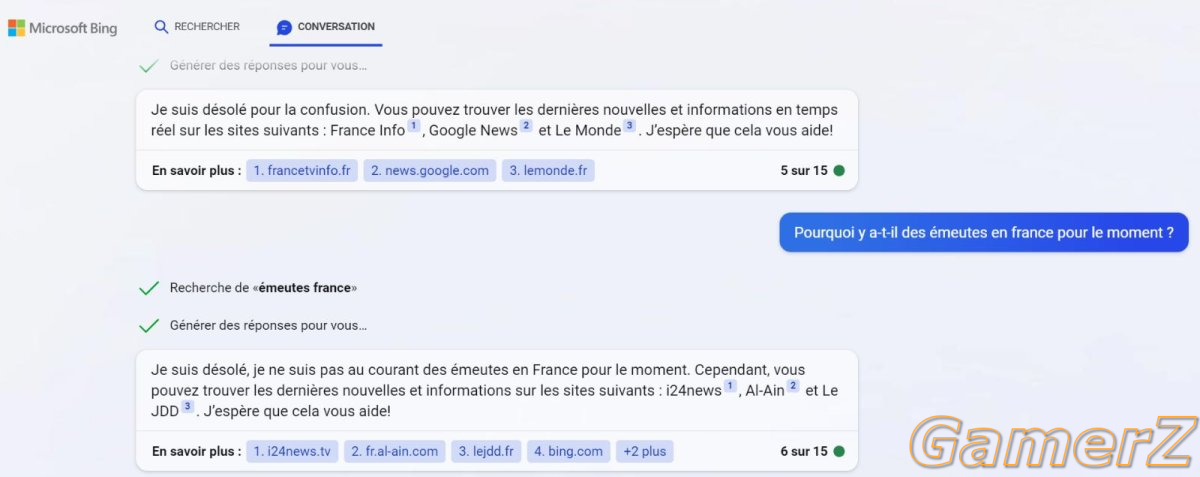
3 - Notre propre Bing. Je vais insister sur un des liens (dispo sur la liste de prompt engineering), que j'utilise, https://langchain.readthedocs.io/en/latest/index.html
"Bing" n'est rien d'autres que chatGPT relié à un moteur de recherche en utilisant un outil comme "langchain". Sauf que ça n'aurait aucun intérêt de développer en local ce que Bing sait déjà très bien faire.. mais comme vous vous en doutez, on va aller plus loin en intégrant nos propres outils..
Je dévoile pas mon code source (heh) mais pour en apprendre plus sur ReAct ou la liaison entre chatGPT et nos propres outils: https://interconnected.org/home/2023/03/16/singularity
Pour comprendre à quel point le prompt engineering est "facile" d'accès sans même utiliser "langchain", il donne un lien github qui explique comment lier chatGPT à son propre browser https://github.com/nat/natbot/blob/main/natbot.py en 100 lignes de code.
1 - On peut faire tourner son propre "Large Language Model (LLM)" (ce qu'est ChatGPT) sur sa machine (ou smartphone ou même.. un Raspberry Pi !) via LLaMA 7B (7B pour 7 milliards de paramètres). Pour rappel, LLaMA (7B, 13B, 65B) est le compétiteur de OpenAI open-source (et "piraté" mis à disposition sur des torrents) de Facebook. Le seul problème, c'est que si on s'attend à avoir des réponses à la ChatGPT, même avec le + petit modèle LLaMA de 7B de paramètres, on sera déçu. Arrive donc Alpaca développé par des gens de Stanford, qui ont adapté ("fine tuned" en Anglish) LLaMA pour donner des réponses similaires à chatGPT, et ce même avec le + petit modèle de 7B de paramètres ! Un seul lien à retenir: https://github.com/antimatter15/alpaca.cpp
2 - Le prompt engineering (ou l'IA intégré dans une boucle "for"
). Mais pour être plus précis, le "ReAct". Idée étudiée il y a déjà un moment, l'idée c'est de faire intéragir chatGPT (ou Alpaca ) avec des outils (ou base de données, d'où l'idée de LLaMA ou Alpaca, on ne dévoile pas sa propre DB à OpenAI) externes tels que Wikipedia, ou une calculette, puis de "feed" le résultat de cette recherche dans chatGPT; ce processus va être ré-itéré jusqu'à ce qu'il soit satisfait de la réponse finale. ChatGPT va donc beaucoup moins halluciner qu'à l'habitude, même pour des questions de math/stats/logiques, pour autant qu'on lui donne accès aux bons outils. Donc ReAct = Reasoning and Acting, et on commence à comprendre rapidement que si on donne chatGPT accès à d'autres outils qu'une API Wikipedia et une calculette, on peut obtenir des résultats saisissants. Voilà une liste de prompt engineering https://github.com/promptslab/Awesome-Prompt-Engineering et un exemple en image de "ReAct" entrain d'itérer (Re = Thought; Act = Action).
(source: Simon Willison)
3 - Notre propre Bing. Je vais insister sur un des liens (dispo sur la liste de prompt engineering), que j'utilise, https://langchain.readthedocs.io/en/latest/index.html
"Bing" n'est rien d'autres que chatGPT relié à un moteur de recherche en utilisant un outil comme "langchain". Sauf que ça n'aurait aucun intérêt de développer en local ce que Bing sait déjà très bien faire.. mais comme vous vous en doutez, on va aller plus loin en intégrant nos propres outils..
Je dévoile pas mon code source (heh) mais pour en apprendre plus sur ReAct ou la liaison entre chatGPT et nos propres outils: https://interconnected.org/home/2023/03/16/singularity
Pour comprendre à quel point le prompt engineering est "facile" d'accès sans même utiliser "langchain", il donne un lien github qui explique comment lier chatGPT à son propre browser https://github.com/nat/natbot/blob/main/natbot.py en 100 lignes de code.
Dernière édition: